Some notes on AES-GCM mode
AES-GCM
Vấn đề với AES thông thường đó chính là nó không có cơ chế xác thực tin nhắn. Tức là kể cả khi ciphertext bị thay đổi thì oracle vẫn thực hiện giải mã hợp lệ.
Vì thế người ta quyết định thêm một kĩ thuật xác thực dùng khóa bí mật - MAC vào trong AES và từ đó ta có AES-GCM. GCM là viết tắt của Galois/Counter Mode và ta sẽ đi tìm hiểu từng phần của nó.
Tài liệu của NIST: AES-GCM
Mọi người nên tham khảo ở đây để nắm được đầy đủ cách xây dựng và implement của AES - GCM. Trong bài mình chỉ liệt kê sơ lại các ý chính nên có thể sẽ có nhiều chỗ hơi tắt.
MAC
Một kĩ thuật xác thực dùng khóa bí mật gọi là MAC ( Message Authentication Code). Có thể trình bày ngắn gọn kĩ thuật này như sau:
$\displaystyle A$ và $\displaystyle B$ có chung một khóa bí mật $\displaystyle k$. Khi $\displaystyle A$ muốn gửi thông điệp $\displaystyle P$ cho $\displaystyle B$, $\displaystyle A$ tính toán MAC như sau: $\displaystyle MAC=C_{k}( P)$. Thông điệp cùng với MAC được gửi cho $\displaystyle B$, sau đó $\displaystyle b$ tiến hành tính toán MAC trên thông điệp nhận được tương tự như $\displaystyle A$ đã tính, sau đó so sánh với MAC nhận được từ $\displaystyle A$.
Nếu như trùng khớp thì:
- $\displaystyle B$ tin chắc rằng thông điệp không bị sửa đổi
- $\displaystyle B$ đảm bảo được rằng thông điệp được gửi một cách hợp pháp từ $\displaystyle A$. Vì chỉ có 2 người sỡ hữu khóa bí mật nên không ai có thể chuẩn bị một thông điệp tương tự
Mã hóa đối xứng như AES cung cấp tính xác thực và được sử dụng rộng rãi nhưng không cung cấp chữ kí số vì cả $\displaystyle A$ và $\displaystyle B$ cùng dùng chung một khóa
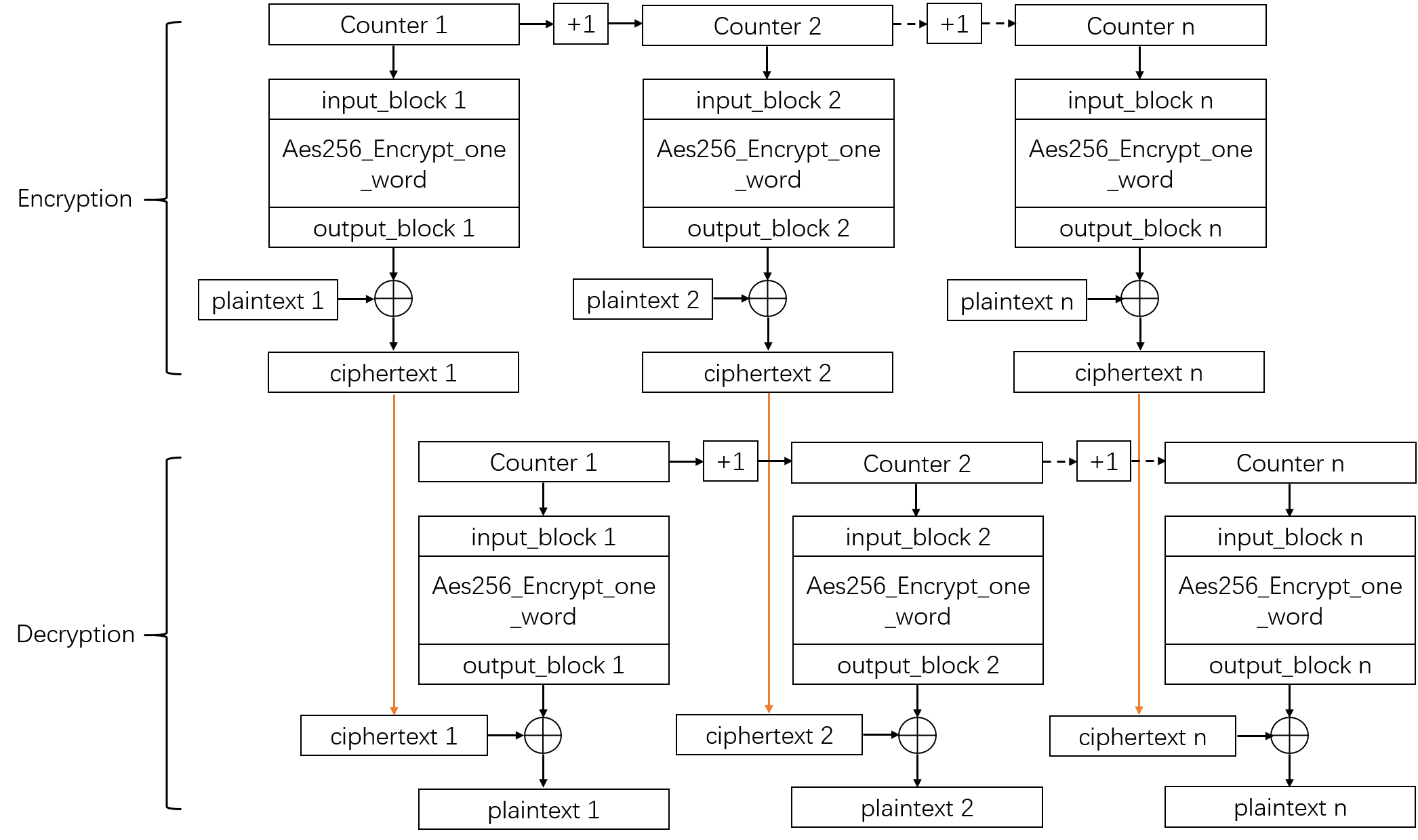
Counter Mode
CTR Mode là viết tắt của Counter Mode. CTR là chế độ mã hóa sử dụng một tập các khối ngõ vào, gọi là các counter, để sinh ra một tập các giá trị ngõ ra. Sau đó, giá trị ngõ ra sẽ được XOR với plaintext để tạo ra ciphertext trong quá trình mã hóa, hoặc XOR với ciphertext để tạo ra plaintext trong quá trình giải mã.
Bằng cách này CTR Mode giúp biến AES từ Block Cipher trở thành Stream Cipher. Mọi người có thể xem sơ đồ hoạt động dưới đây của CTR Mode.
Input sẽ bao gồm 2 phần đó là Nonce và một bộ đếm. Nonce là number used once hoặc là IV. Nó sẽ được tạo ra ngẫu nhiên và được sử dụng một lần duy nhất. Ngõ vào của AES Encryption sẽ là Input(i) = Nonce || CTR(i) .
Counter sẽ nối vào sau Nonce và Input này sẽ được mã hóa bằng AES với một key $k$. Output sẽ được XOR với Plaintext và tiếp tục như vậy cho các Block khác. CTR(i) sẽ tăng dần khi chuyển sang các Block.
Galois Field
Trước tiên ta cần hiểu trường là gì
Trường. Cho $\displaystyle A$ là một trường nếu như $\displaystyle A$ là một vành giao hoán có đơn vị khác không và mọi phần tử khác không của $\displaystyle A$ đều khả nghịch đối với phép nhân, tức là $\displaystyle A$ là một thể với phép nhân giao hoán.
Vành đa thức hữu hạn biến. Cho $\displaystyle A$ là một vành giao hoán có đơn vị là $\displaystyle 1$. Khi đó với một kí hiệu $\displaystyle X$, ta gọi $\displaystyle A[ X]$ là tập các biểu thức có dạng
trong đó $\displaystyle a_{i} \in A$ với mọi $\displaystyle 0\leqslant i=n,n\in \mathbb{N}$. Giả sử
Ta định nghĩa phép nhân và phép cộng đơn giản như sau:
Phép cộng:
Phép nhân:
Vành $\displaystyle A[ X]$ được gọi là vành các đa thức của biến $\displaystyle X$ lấy hệ tử trong $\displaystyle A$ (hoặc vành đa thức của biến $\displaystyle X$ trên $\displaystyle A$) còn các phần tử của $\displaystyle A[ X]$ được gọi là các đa thức của biến $\displaystyle X$ lấy hệ tử trong $\displaystyle A$. Đa thức
được gọi là có bậc $\displaystyle n$ và viết là $\displaystyle degf=n$.
Trong AES-GCM các phép tính toán sẽ làm việc trên một trường đặc biệt, kí hiệu là $\displaystyle \mathbb{F}_{2}$. Trường này có đặc số là 2. Ta cùng đi qua một số ví dụ để hiểu rõ hơn về cách hoạt động của trường này.
Đầu tiên ta có phiên bản đơn giản nhất của nó chính là trường hữu hạn $\displaystyle GF( 2)$. Trường này bao gồm 2 phần tử là $\displaystyle{0,1}$. Phép cộng trên trường này chính là phép XOR logic. Và tương tự phép nhân cũng chính là phép AND logic.
Hiểu đơn giản là ta lấy 2 phần tử trên trường này sau đó thực hiện phép cộng/phép nhân số học như thông thường, sau đó kết quả sẽ được lấy theo modulo 2.

Vì AES-GCM làm việc với các khối có độ lớn là 128 bits cho nên ta cần phải thực hiện tính toán trên trường hữu hạn $\displaystyle GF\left( 2^{128}\right)$ gồm có $\displaystyle 2^{128}$ phần tử khác nhau.
Để tính toán thì ta cần định nghĩa phép nhân cùng phép cộng trên trường này. Một cách để biểu diễn đó là ta xem các phần tử trong trường $\displaystyle GF\left( 2^{128}\right)$ như là một đa thức với các hệ số trong trường $\displaystyle \mathbb{F}_{2}$.
Ví dụ với $\displaystyle 1011$ ta sẽ viết lại thành $\displaystyle a( x) =x^{3} +x+1$.
Như vậy mỗi phần tử trong trường $\displaystyle GF\left( 2^{128}\right)$ sẽ được viết dưới dạng nhị phân và mỗi bit sẽ cho ta biết được thông tin là đơn thức $\displaystyle x^{i}$ có thuộc vào đa thức hay không. Trong GCM thì bit sẽ được viết theo dạng big endian, tức là bit có trọng số cao hơn thì nằm ở trước. Cụ thể, MSB của chuỗi bit sẽ biểu diễn cho $\displaystyle x^{0}$, bit tiếp theo sẽ là $\displaystyle x^{1}$ và cứ như vậy cho tới $\displaystyle x^{127}$. Một số ví dụ:
-
$\displaystyle 1$ sẽ tương đương với $\displaystyle 100000….$
-
$\displaystyle x^{4} +x$ sẽ tương đương với $\displaystyle 01001000….$
Và tương tự.
Tiếp theo ta sẽ định nghĩa phép nhân và cộng trên trường này.
Đối với phép cộng thì ta định nghĩa tương tự như khi làm việc trên trường $\displaystyle GF( 2)$ đó là cộng lần lượt từng đơn thức có bậc bằng nhau và sau đó XOR hệ số đứng trước chúng lại. Ví dụ ta có $\displaystyle a( x) =x^{2} +x\in GF\left( 2^{128}\right)$ và $\displaystyle b( x) =x^{4} +x^{2} +1\in GF\left( 2^{128}\right)$. Ta tính được
Ta chỉ giữ lại những đơn thức nào chỉ xuất hiện tại 1 trong 2 đa thức.
Vì phép cộng được định nghĩa như trên cho nên ta có thể đảm bảo rằng $\displaystyle \deg c\leqslant 127$ và là một đa thức hợp lệ trong trường $\displaystyle GF\left( 2^{128}\right)$. Nhưng đối với phép nhân thì phức tạp hơn một chút.
Chẳng hạn ta muốn thực hiện phép nhân giữa $\displaystyle a( x) =x^{126} +x$ và $\displaystyle b( x) =x^{3} +x^{2}$. Nếu ta thực hiện phép nhân như thông thường
Đa thức $\displaystyle c( x)$ thu được có bậc là 129 và rõ ràng không phải là một phần tử hợp lệ trên trường $\displaystyle GF\left( 2^{128}\right)$. Để giải quyết vấn đề này thì ta cần sử dụng một đa thức gọi là đa thức bất khả quy để lấy modulo nhằm giảm bậc và đưa $\displaystyle c( x)$ về lại trường $\displaystyle GF\left( 2^{128}\right)$. Lý do ta chọn đa thức bất khả quy là để $\displaystyle \mathbb{F}_{2}[ X] /q( x)$ tạo thành một trường thương và có một đẳng cấu
Trong GCM thì ta sẽ sử dụng $\displaystyle q( x) =x^{128} +x^{7} +x^{2} +x+1$. Hiểu đơn giản thì việc lấy modulo một đa thức bất khả quy tương tự như khi ta lấy modulo một số nguyên tố để tạo ra trường $\mathbb{F}_p$ vậy.
Còn thuật toán chia lấy dư thì hơi dài dòng quá nên mình sẽ không đề cập ở đây.
Đầy đủ hơn về phần giải thích này mọi người có thể tham khảo các tài liệu sau:
- https://www.isec.tugraz.at/wp-content/uploads/teaching/mfc/ghash_Kales.pdf
- https://www.lirmm.fr/arith18/papers/kobayashi-AlgorithmInversionUsingPolynomialMultiplyInstruction.pdf
Thuật toán
Sơ đồ thuật toán của GCM như sau:
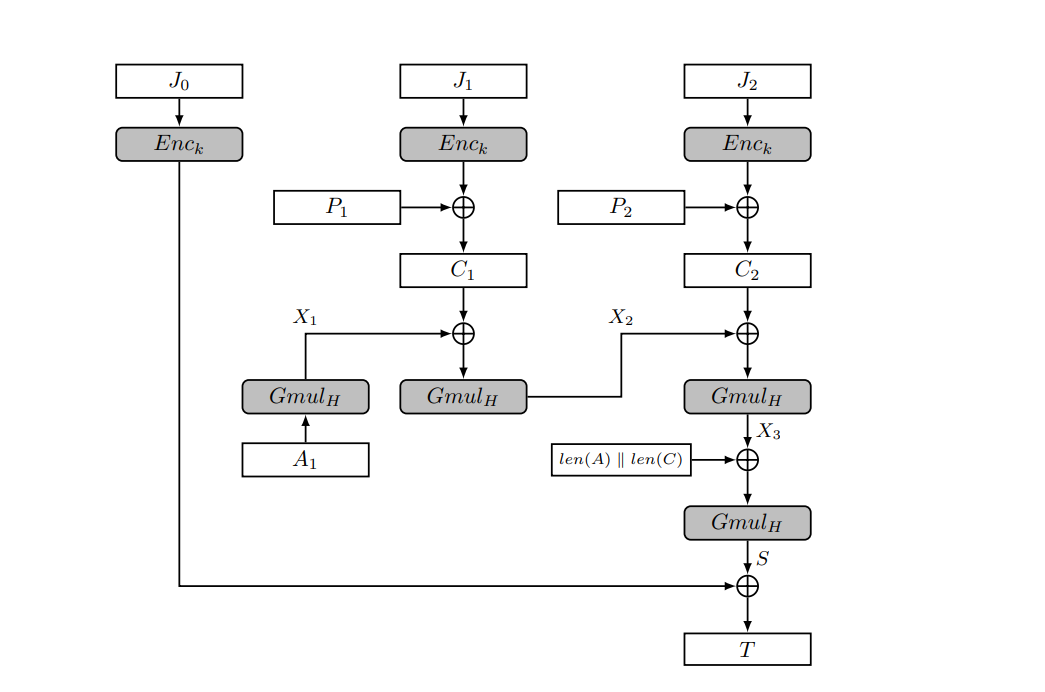
Toàn bộ quá trình diễn ra như sau: Đối với message có $\displaystyle n$ blocks:
Bước 1. Khởi tạo một $\displaystyle IV$ có độ dài 96 bits
Bước 2. Counter block $\displaystyle J_{i}$ sau đó sẽ được tạo bằng cách lấy $\displaystyle J_{i} =IV\mid \mid cnt$ và $\displaystyle cnt=( i+1)\bmod 2^{32}$ với mỗi $\displaystyle i\in {1,…,n}$
Bước 3. Mỗi ciphertext sẽ được tính bởi $\displaystyle C_{i} =P_{i} \oplus Enc_{k}( J_{i})$ trong đó $\displaystyle Enc_{k}$ là AES-Encryptor với key là $\displaystyle k$.
Tiếp đến là hàm GHASH. Để tính tag $\displaystyle T$ của AES-GCM thì ta cần sử dụng một hàm gọi là GHASH. Cụ thể cách hoạt động như sau:
Đầu vào của GHASH cần một authenticated key $\displaystyle H$ có độ dài 128 bits. Key $\displaystyle H$ được tạo bằng cách mã hóa 16 NULL bytes bằng AES với key $\displaystyle k$. Sau đó giá trị này sẽ được chuyển thành đa thức và được sử dụng trong suốt quá trình tính toán GHASH.
Để tính, ta cần chuyển dữ liệu cần xác thực thành các khối 128 bits, và sẽ pad thêm các NULL bytes nếu như chưa đạt đủ chiều dài mong muốn. Ta sẽ làm tương tự với additional authenticated data.
Thông tin cuối cùng mà ta cần thêm vào đó là độ lớn của data. Ta sẽ thêm vào một block ở cuối chứa thông tin về độ dài của additional authenticated data và ciphertext.
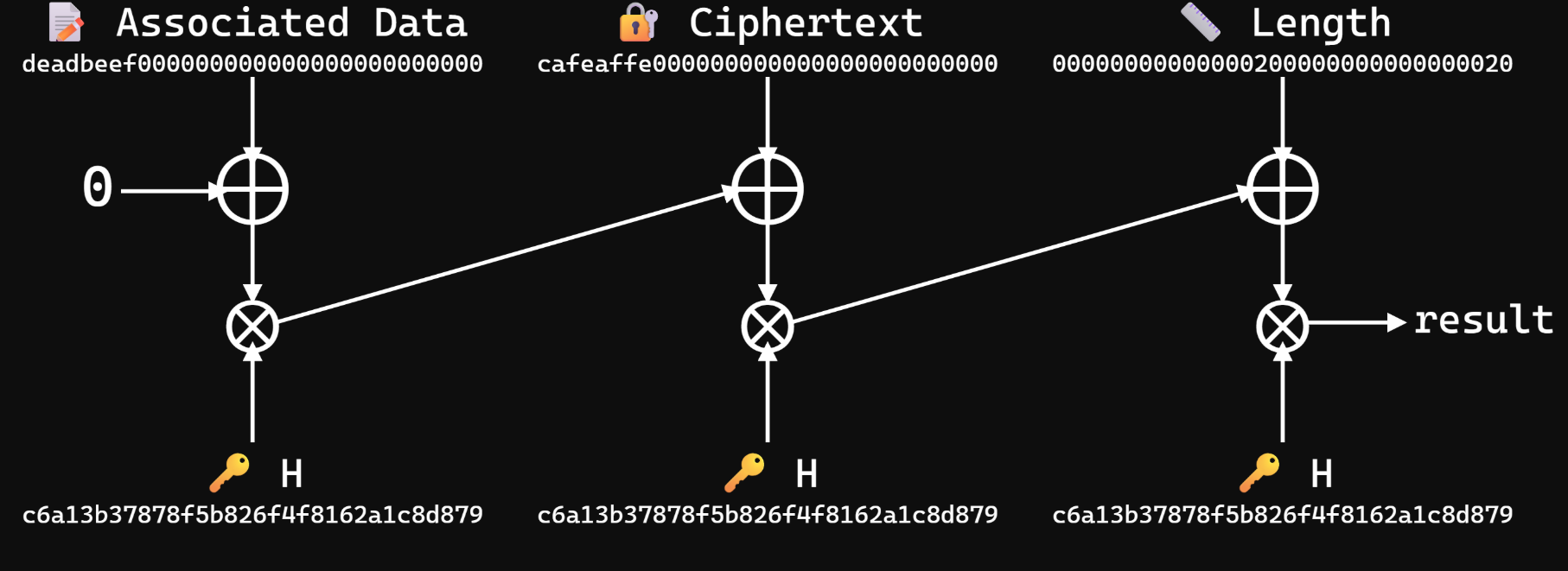
Ở vòng đầu tiên ta sẽ khởi tạo một phần tử $\displaystyle Q\in GF\left( 2^{128}\right)$ và $\displaystyle Q=0$. Sau đó ta sẽ lấy giá trị này cộng với AAD. Kết quả sau đó được nhân với key $\displaystyle H$ và trở thành đầu vào cho vòng tiếp theo và cứ thế lặp lại.
Giả sử ta cần tính cho 3 block $\displaystyle U_{0} ,U_{1} ,U_{2}$. Ở bước đầu tiên ta sẽ có được $\displaystyle Q\leftarrow U_{0} \times H$. Sang bước thứ hai ta sẽ có $\displaystyle Q\leftarrow ( Q+U_{1}) \times H$. Cứ như vậy ta sẽ được
Tag $\displaystyle T$ sau đó sẽ được tính bởi $\displaystyle T=Q+Enc_{k}( J_{0})$.
Một vài trường hợp có thể sẽ không có AAD ở đầu.
Công thức tổng quát sẽ là như sau:
Với $H=E_K(0^{128}), s=E_K(J_0)$ với $J_0 = nonce \mid \mid 0^{31} \mid \mid 1$ . Tiếp theo, tạo các block $A_1,…,A_m$ từ AAD và $C_1,C_2,…,C_n$ từ ciphertext (được nullpad) và block độ dài $L$, thì lúc này ta có
với $s$ là keystream cho block này và $S$ được tính bởi:
Code cho thuật toán trên:
from sage.all import *
from Crypto.Util.number import bytes_to_long, long_to_bytes
from Crypto.Cipher import AES
# helper functions
a = GF(2)['a'].gen()
F = GF(2**128, name = 'x' ,modulus = a**128+a**7+a**2+a+1)
def nullpad(msg):
return bytes(msg) + b'\x00' *(-len(msg) % 16)
def un_nullpad(msg):
return bytes(msg).strip(b'\x00')
c = b'test'
assert un_nullpad(nullpad(c)) == c
def bytes_to_n(b):
v = int.from_bytes(nullpad(b),'big')
return int(f"{v:0128b}"[::-1],2)
def bytes_to_poly(b):
return F.from_integer(bytes_to_n(b))
def poly_to_n(p):
v = p.to_integer()
return int(f"{v:0128b}"[::-1],2)
def poly_to_bytes(p):
return poly_to_n(p).to_bytes(16,'big')
def length_block(lad, lct):
return int(lad * 8).to_bytes(8, 'big') + int(lct * 8).to_bytes(8, 'big')
def ghash(H, A, C):
X = F(0)
for i in range(0, len(A) + (-len(A) % 16), 16):
B = (A + b'\x00'*16)[i:i+16]
X = (X + bytes_to_poly(B)) * H
for i in range(0, len(C) + (-len(C) % 16), 16):
B = (C + b'\x00'*16)[i:i+16]
X = (X + bytes_to_poly(B)) * H
L = bytes_to_poly(length_block(len(A),len(C)))
X = (X + L) * H
return X
def calculate_tag(key, ct, nonce, ad):
E = AES.new(key, AES.MODE_ECB).encrypt
H = bytes_to_poly(E(b'\x00'*16))
if len(nonce) == 12:
J0 = nonce + b'\x00\x00\x00\x01'
else:
J0_poly = ghash(H, b"", nonce)
J0 = poly_to_bytes(J0_poly)
S = ghash(H, ad, ct)
tag = S + bytes_to_poly(E(J0))
return poly_to_bytes(tag)
def check():
key = os.urandom(16)
nonce = os.urandom(16)
ad = os.urandom(os.urandom(1)[0])
pt = os.urandom(os.urandom(1)[0])
cipher = AES.new(key, AES.MODE_GCM, nonce)
cipher.update(ad)
ct, tag = cipher.encrypt_and_digest(pt)
assert tag == calculate_tag(key, ct, nonce, ad)
print("OK")
# Forbidden attack
def recover_possible_auth_keys(a1, c1, t1, a2, c2, t2):
'''
2 msgs được mã hóa bởi cùng 1 Auth key là H = Enc_k(null)
Chung authkey thì tức là chung key k
a1: AAD của msg1
c1: ct của msg1
t1: Auth Tag của msg1
tương tự
'''
h = F["h"].gen()
s1 = ghash(h,a1,c1) + bytes_to_poly(t1)
s2 = ghash(h,a2,c2) + bytes_to_poly(t2)
for h, _ in (s1+s2).roots():
yield h
def forge_tag(h, a, c, t, target_a, target_c):
'''
giả mạo một tag hợp lệ cho cặp (target_a, target_c) từ một bộ (h,a,c,t) biết trước
điều kiện áp dụng là cả hai phải dùng chung nonce
'''
s = bytes_to_poly(t) + ghash(h,a,c)
forged = s + ghash(h,target_a, target_c)
return poly_to_bytes(forged)
check()
Nonce Reuse
Ta đã biết cách AES-GCM tạo tag $\displaystyle T$. Vậy chuyện gì sẽ xảy ra nếu như ta tạo tag cho 2 messages khác nhau mà vẫn giữ nguyên nonce.
Giả sử ta muốn tính $\displaystyle T_{1} ,T_{2}$ bằng cách sử dụng lại cùng một key và nonce.
Với messages đầu tiên ta sẽ có các block $U_{1,0},\; U_{1,1},\; U_{1,2}$ và tương tự $U_{2,0},\; U_{2,1},\; U_{2,2}$.
Ta có
Vì dùng chung nonce cho nên keystream $\displaystyle S$ đầu tiên là giống nhau. Như vậy ta có thể làm triệt tiêu đi giá trị này bằng cách cộng hai tag lại với nhau
Ta có thể biết được giá trị của $\displaystyle T1,T2$ cũng như $\displaystyle U_{1},U_{2}$. Bây giờ nếu ta xem biểu thức trên như một đa thức theo $\displaystyle H$ thì ta có thể giải tìm nghiệm và khôi phục lại được $\displaystyle H$. Việc tìm lại $\displaystyle H$ giúp ta giả mạo được tin nhắn của người gửi bằng cách tính lại GHASH của tin nhắn đó.
Tiếp theo ta sẽ giải quyết một số challenge về AES-GCM
Practice
Chall 1
Source code của bài:
from Crypto.Cipher import AES
import os
IV = ?
KEY = ?
FLAG = ?
@chal.route('/forbidden_fruit/decrypt/<nonce>/<ciphertext>/<tag>/<associated_data>/')
def decrypt(nonce, ciphertext, tag, associated_data):
ciphertext = bytes.fromhex(ciphertext)
tag = bytes.fromhex(tag)
header = bytes.fromhex(associated_data)
nonce = bytes.fromhex(nonce)
if header != b'CryptoHack':
return {"error": "Don't understand this message type"}
cipher = AES.new(KEY, AES.MODE_GCM, nonce=nonce)
encrypted = cipher.update(header)
try:
decrypted = cipher.decrypt_and_verify(ciphertext, tag)
except ValueError as e:
return {"error": "Invalid authentication tag"}
if b'give me the flag' in decrypted:
return {"plaintext": FLAG.encode().hex()}
return {"plaintext": decrypted.hex()}
@chal.route('/forbidden_fruit/encrypt/<plaintext>/')
def encrypt(plaintext):
plaintext = bytes.fromhex(plaintext)
header = b"CryptoHack"
cipher = AES.new(KEY, AES.MODE_GCM, nonce=IV)
encrypted = cipher.update(header)
ciphertext, tag = cipher.encrypt_and_digest(plaintext)
if b'flag' in plaintext:
return {
"error": "Invalid plaintext, not authenticating",
"ciphertext": ciphertext.hex(),
}
return {
"nonce": IV.hex(),
"ciphertext": ciphertext.hex(),
"tag": tag.hex(),
"associated_data": header.hex(),
}
Phân tích source code: Bài gồm 2 route là decrypt và encrypt.
Hàm encrypt sẽ nhận đầu vào của ta dưới dạng hex sau đó sẽ trả về ciphertext cùng với tag và có thêm một điều kiện là trong plaintext của ta không được chứa b'flag'. Server sẽ trả về lại cho ta nonce, ciphertext, tag và AAD. AAD và nonce trong bài này là cố định và không thay đổi và để lấy được flag thì ta cần forge đoạn tin nhắn chứa b'give me the flag'.
Quá trình tính toán như sau: Đầu tiên ta có
trong đó $\displaystyle c_{1} ,c_{2}$ là hai ciphertext.
Xét
Ta muốn tính $\displaystyle T_{3}$ của bản mã $\displaystyle c_{3}$ thì ta sẽ có được
Như vậy $\displaystyle T_{3} =X+c_{3} H^{2}$. Ta có được $\displaystyle X$ và $H$ như sau:
Như vậy ta sẽ tính lại được $\displaystyle T_{3}$. Còn về phần $\displaystyle c_{3}$ ta có thể gửi lên route encrypt để lấy về. Code giải như sau:
from sage.all import *
from Crypto.Util.number import bytes_to_long, long_to_bytes
from Crypto.Cipher import AES
from pwn import *
from tqdm import tqdm
import requests
import json
context.log_level = 'debug'
# helper functions
a = GF(2)['a'].gen()
F = GF(2**128, name = 'x' ,modulus = a**128+a**7+a**2+a+1)
def nullpad(msg):
return bytes(msg) + b'\x00' *(-len(msg) % 16)
def un_nullpad(msg):
return bytes(msg).strip(b'\x00')
c = b'test'
assert un_nullpad(nullpad(c)) == c
def bytes_to_n(b):
v = int.from_bytes(nullpad(b),'big')
return int(f"{v:0128b}"[::-1],2)
def bytes_to_poly(b):
return F.from_integer(bytes_to_n(b))
def poly_to_n(p):
v = p.to_integer()
return int(f"{v:0128b}"[::-1],2)
def poly_to_bytes(p):
return poly_to_n(p).to_bytes(16,'big')
def length_block(lad, lct):
return int(lad * 8).to_bytes(8, 'big') + int(lct * 8).to_bytes(8, 'big')
def calculate_tag(key, ct, nonce, ad):
y = AES.new(key, AES.MODE_ECB).encrypt(bytes(16))
s = AES.new(key, AES.MODE_ECB).encrypt(nonce + b"\x00\x00\x00\x01")
assert len(nonce) == 12
y = bytes_to_poly(y)
l = length_block(len(ad), len(ct))
blocks = nullpad(ad) + nullpad(ct)
bl = len(blocks) // 16
blocks = [blocks[16 * i:16 * (i + 1)] for i in range(bl)]
blocks.append(l)
blocks.append(s)
tag = F(0)
for exp, block in enumerate(blocks[::-1]):
tag += y**exp * bytes_to_poly(block)
tag = poly_to_bytes(tag)
return tag
# def check():
# key = os.urandom(16)
# nonce = os.urandom(12)
# ad = os.urandom(os.urandom(1)[0])
# pt = os.urandom(os.urandom(1)[0])
# cipher = AES.new(key, AES.MODE_GCM, nonce)
# cipher.update(ad)
# ct, tag = cipher.encrypt_and_digest(pt)
# assert tag == calculate_tag(key, ct, nonce, ad)
# if __name__ == "__main__":
# check()
def solve():
def encrypt(plaintext):
url = 'http://aes.cryptohack.org/forbidden_fruit/encrypt/'
url += plaintext.hex()
r = requests.get(url).json()
if "error" in r:
return None, bytes.fromhex(r["ciphertext"])
return bytes.fromhex(r["nonce"]), bytes.fromhex(r["ciphertext"]), bytes.fromhex(r["tag"]), bytes.fromhex(r["associated_data"])
def decrypt(nonce,ciphertext,tag,associated_data):
url = 'http://aes.cryptohack.org/forbidden_fruit/decrypt/'
url += nonce.hex() + '/' + ciphertext.hex() + '/' + tag + '/' + associated_data.hex()
r = requests.get(url).json()
return bytes.fromhex(r["plaintext"])
msg1 = b'\x00' * 16
msg2 = b'\x01' * 16
r1 = encrypt(msg1)
r2 = encrypt(msg2)
A = r1[3]
print(A)
nonce = r1[0]
c1, T1 = r1[1], r1[2]
c2, T2 = r2[1], r2[2]
c1 = bytes_to_poly(c1)
c2 = bytes_to_poly(c2)
T1 = bytes_to_poly(T1)
T2 = bytes_to_poly(T2)
H_2 = (T1-T2)/(c1-c2)
assert T1 - c1*H_2 == T2 - c2*H_2
X = T1 - c1*H_2
msg3 = b'give me the flag'
c3 = encrypt(msg3)[1]
T3 = X + bytes_to_poly(c3)*H_2
print(T3)
tag3 = poly_to_n(T3)
print(decrypt(nonce, c3, hex(tag3)[2:],A).decode())
if __name__ == "__main__":
solve()
Chall 2
Source code của bài:
from Crypto.Cipher import AES
import os, time, sys, random
from flag import flag
passphrase = b'HungryTimberWolf'
def encrypt(msg, passphrase, niv):
msg_header = 'EPOCH:' + str(int(time.time()))
msg = msg_header + "\n" + msg + '=' * (15 - len(msg) % 16)
aes = AES.new(passphrase, AES.MODE_GCM, nonce = niv)
enc = aes.encrypt_and_digest(msg.encode('utf-8'))[0]
return enc
def die(*args):
pr(*args)
quit()
def pr(*args):
s = " ".join(map(str, args))
sys.stdout.write(s + "\n")
sys.stdout.flush()
def sc():
return sys.stdin.readline().strip()
def main():
border = "+"
pr(border*72)
pr(border, " hi wolf hunters, welcome to the most dangerous hunting ground!! ", border)
pr(border, " decrypt the encrypted message and get the flag as a nice prize! ", border)
pr(border*72)
niv = os.urandom(random.randint(1, 11))
flag_enc = encrypt(flag, passphrase, niv)
while True:
pr("| Options: \n|\t[G]et the encrypted flag \n|\t[T]est the encryption \n|\t[Q]uit")
ans = sc().lower()
if ans == 'g':
pr(f'| encrypt(flag) = {flag_enc.hex()}')
elif ans == 't':
pr("| Please send your message to encrypt: ")
msg_inp = sc()
enc = encrypt(msg_inp, passphrase, niv).hex()
pr(f'| enc = {enc}')
elif ans == 'q':
die("Quitting ...")
else:
die("Bye ...")
if __name__ == '__main__':
main()
Phân tích:
passphrase = b'HungryTimberWolf'
def encrypt(msg, passphrase, niv):
msg_header = 'EPOCH:' + str(int(time.time()))
msg = msg_header + "\n" + msg + '=' * (15 - len(msg) % 16)
aes = AES.new(passphrase, AES.MODE_GCM, nonce = niv)
enc = aes.encrypt_and_digest(msg.encode('utf-8'))[0]
return enc
Ở phần đầu tiên ta được cho một passphrase, passphrase này sẽ được sử dụng trong hàm encrypt. Logic của hàm encrypt như sau: Nó nhận vào 3 tham số msg, pass và niv. Sau đó tạo một msg_header bao gồm 2 phần đó là EPOCH: và thời gian hiện tại. Tiếp theo nó sẽ nối msg_header với msg và padding thêm các kí tự = ở cuối để đảm bảo độ dài là bội số của 16. Cuối cùng nó sẽ mã hóa message bằng AES-GCM với key là pass và nonce là niv.
Kết quả trả về cuối cùng sẽ là ciphertext đã được mã hóa. Ta không được cho biết tag của AES-GCM.
Tiếp theo hãy thử xem logic của hàm main như thế nào:
niv = os.urandom(random.randint(1, 11))
flag_enc = encrypt(flag, passphrase, niv)
Server tạo một niv và tính toán ciphertext của flag. Sau đó nó cho ta chọn 3 option là G,T,Q. Với option G thì server sẽ trả về ciphertext của flag. Với option T thì server sẽ cho phép ta gửi lên một msg bất kì và trả về ciphertext của msg đó còn với option Q thì server sẽ thoát.
Vậy làm sao để ta lấy lại flag? Vấn đề nằm ở hàm sinh iv. Ở đây nó lấy
niv = os.urandom(random.randint(1,11))
Cho nên sẽ có xác suất niv sẽ chỉ có độ dài là 1 bytes tức là 256 khả năng khác nhau. Vậy nên có thể thử bruteforce được
Solve script:
from pwn import *
from utils import *
context.log_level = 'debug'
passphrase = b'HungryTimberWolf'
flags = []
for _ in range(50):
io = process(['python3', 'chall.py'])
io.sendline(b'G')
io.recvuntil(b'= ')
flag_enc = io.recvline().strip()
flags.append(flag_enc)
io.close()
print(flags)
def solve(lst):
for iv in range(256):
A = AES.new(passphrase, AES.MODE_GCM, nonce = bytes([iv]))
flag = A.decrypt(bytes.fromhex(lst.decode()))
if b'W1' in flag:
print(flag)
break
if __name__ == '__main__':
for lst in flags:
solve(lst)
Chall 3
Source code:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import zlib
import base64
from Crypto.Cipher import AES
KEY = os.urandom(16)
USED_NONCES = []
ADMIN_SECRET = b"Glacier CTF Open"
ADMIN_LOGS = ""
NORMAL_LOGS = ""
MAX_STORAGE = 1 << 16
def decrypt(ct: bytes, nonce: bytes, tag: bytes) -> bytes:
ad = b"GlacierCTF2025"
cipher = AES.new(KEY, AES.MODE_GCM, nonce=nonce)
cipher.update(ad)
try:
decrypted = cipher.decrypt_and_verify(ct, tag)
except:
raise ValueError("Invalid tag")
return decrypted
def encrypt(pt: bytes, nonce: bytes = os.urandom(16)):
ad = b"GlacierCTF2025"
cipher = AES.new(KEY, AES.MODE_GCM, nonce=nonce)
cipher.update(ad)
ct, tag = cipher.encrypt_and_digest(pt)
return ct, nonce, tag
def test_init():
global ADMIN_LOGS
pt = b"Hello GlacierCTF"
ct, nonce, tag = encrypt(pt)
assert pt == decrypt(ct, nonce, tag)
ADMIN_LOGS += f"[+] Nonce: {base64.b64encode(nonce).decode()}\n"
ADMIN_LOGS += f"[+] Tag: {base64.b64encode(tag).decode()}\n"
def get_size() -> int:
global ADMIN_LOGS, NORMAL_LOGS, USED_NONCES
full_state: bytes = ADMIN_LOGS.encode() + NORMAL_LOGS.encode()
return len(zlib.compress(full_state)) + len(USED_NONCES)*16
def print_help():
print("[0] Encrypt a file")
print("[1] Access admin files")
def main():
global NORMAL_LOGS,ADMIN_LOGS
print("[+] Welcome to the Glacier encryption service")
test_init()
print(ADMIN_LOGS)
while get_size() < MAX_STORAGE:
try:
print_help()
choice = int(input("Choose action:\n> "))
if choice == 0:
pt = bytes.fromhex(input("Plaintext:\n> "))
nonce = bytes.fromhex(input("Nonce:\n> "))
if nonce in USED_NONCES or ADMIN_SECRET in pt:
return
USED_NONCES.append(nonce)
ct, nonce, tag = encrypt(pt, nonce)
NORMAL_LOGS = f"{pt.hex()=} = {ct.hex()=}, {tag.hex()=}"
print(NORMAL_LOGS)
NORMAL_LOGS = f"{pt}"
print(f"[+] Storage left: {get_size()}/{MAX_STORAGE} bytes")
elif choice == 1:
ct = bytes.fromhex(input("Ciphertext:\n> "))
nonce = bytes.fromhex(input("Nonce:\n> "))
tag = bytes.fromhex(input("Tag:\n> "))
pt = decrypt(ct, nonce, tag)
if ADMIN_SECRET in pt:
with open("flag.txt", "r") as flag:
print(f"{flag.read()}")
return
else:
return
except:
return
return
if __name__ == "__main__":
main()
Phân tích và tóm tắt: Bài chia làm 2 phần. Đầu tiên ta phải tìm cách leak được giá trị nonce và tag của admin. Mấu chốt nằm ở hàm get_size() -> int
def get_size() -> int:
global ADMIN_LOGS, NORMAL_LOGS, USED_NONCES
full_state: bytes = ADMIN_LOGS.encode() + NORMAL_LOGS.encode()
return len(zlib.compress(full_state)) + len(USED_NONCES)*16
Vậy hàm này đang làm gì? Hàm này sẽ trả về cho ta biết độ dài của logs đang có sẵn trên server. Mỗi lần chạy nó sẽ tính zlib.compress(data) rồi cộng với len(USED_NONCES)*16 - giá trị này sẽ tăng lên sau mỗi lên ta gọi tới server. Khi gọi đến server thì nó sẽ cho ta 2 option. Option đầu tiên là để gửi plaintext và nonce của ta tới server. Nó sẽ mã hóa các giá trị trên và trả về ct, nonce, tag. Option 2 được dùng để leak flag từ server.
Mọi người để ý thì khi gọi xong option 1 nó cũng sẽ trả về cho ta thêm thông tin của hàm get_size() với NORMAL_LOGS lúc này là plaintext mà ta nhập vào
print(f"[+] Storage left: {get_size()}/{MAX_STORAGE} bytes")
Nếu mọi người có từng làm qua bài tập này trên CryptoHack : https://aes.cryptohack.org/ctrime/ thì biết ngay được trick để giải bài này.
Hàm zlib theo mình hiểu thì nó sẽ rút gọn bớt đi các ký tự trùng lặp, sau đó sẽ nén lại.
Mọi người có thể thử chạy để thấy sự khác biệt khi nó rút gọn các đầu vào khác nhau:
import zlib
known_flag="crypto{CRIM"
known_flag=known_flag.encode()
print(len(zlib.compress(known_flag)))
print(len(zlib.compress(known_flag+b'crypto{CRIM')))
print(len(zlib.compress(known_flag+b'crypto{CRIN')))
print(len(zlib.compress(known_flag+b'crypto{CRIK')))
Phần padding thêm giống với bản gốc càng nhiều thì độ dài càng ngắn. Bài trên kia cũng tương tự. Mình sẽ gửi nhiều request đến rồi đó xem đầu vào nào làm cho độ dài của get_size() là nhỏ nhất thì đó chính là kí tự của nonce và admin_tag. Sau khi có được nonce và admin_tag rồi thì mình thực hiện AES - GCM Nonce Reuse Attacks để tính lại GHASH là oke.
Solve script:
from gcm_exploit import *
from pwn import *
import os
LOCAL = True
if not LOCAL:
r = remote("challs.glacierctf.com",13373,timeout=5)
else:
r = process(["python3","aes.py"])
data = r.recvuntil(b'Choose action:')
print(data)
with open("output.txt","w") as f:
f.write(str(data))
# r.recvuntil(b'> ')
# r.sendline(str(0))
# r.recvuntil(b'Plaintext:')
# pt = b"[+] Nonce: " + b"A" * 20
# pt = pt.hex()
# r.sendlineafter(b'> ', str(pt))
# r.interactive()
from Crypto.Cipher import AES
ADMIN_SECRET = b"Glacier CTF Open"
MAX_STORAGE = 1 << 16
ad = b"GlacierCTF2025"
known_nonce = ""
alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
queries = 0
def query_oracle(pt:bytes):
global queries # 344 last time
r.recvuntil(b'> ')
r.sendline(str(0))
r.recvuntil(b'Plaintext:')
pt_ = pt.hex().encode()
nonce = os.urandom(16).hex().encode()
r.sendlineafter(b'> ', pt_)
r.recvuntil(b'Nonce:')
r.sendlineafter(b'> ', nonce)
r.recvuntil(b'Storage left:')
line = r.recvline().strip()
curr = int(line.split(b'/')[0])
queries +=1
eff = curr - 16*queries
return eff
# lấy lại nonce trước
for pos in range(22):
best_ch = None
base_sz = None
for ch in alphabet:
cand = known_nonce + ch
pt = (b"[+] Nonce: " + cand.encode() + b"X") * 5
sz = query_oracle(pt)
if base_sz is None:
base_sz = sz
best_ch = ch
continue
# nếu thấy nhỏ hơn baseline -> chọn luôn, không cần thử tiếp
if sz < base_sz:
best_ch = ch
base_sz = sz
break
known_nonce += best_ch
log.success(f"[nonce_admin prefix] {known_nonce}")
known_tag = ""
# lấy lại tag
# for pos in range(22): # 16 bytes -> base64 cũng 24 ký tự
# best_ch = None
# best_sz = None
# for ch in alphabet:
# cand = known_tag + ch
# block = (b"[+] Tag: " + cand.encode() + b"X")*5
# pt = block * 16
# sz = query_oracle(pt)
# log.info(f"[tag pos {pos}], try {cand!r} -> size {sz}")
# if best_sz is None or sz < best_sz:
# best_sz = sz
# best_ch = ch
# known_tag += best_ch
# log.success(f"[tag_admin prefix] {known_tag}")
for pos in range(22):
base_sz = None
best_ch = None
for ch in alphabet:
cand = known_tag + ch
pt = (b"[+] Tag: " + cand.encode() + b"X") * 5
sz = query_oracle(pt)
if base_sz is None:
base_sz = sz
best_ch = ch
continue
if sz < base_sz:
base_sz = sz
best_ch = ch
break
known_tag += best_ch
log.success(f"[tag_admin prefix] {known_tag}")
known_nonce = known_nonce + "=="
known_tag = known_tag + "=="
print(known_nonce,"\n")
print(known_tag)
import base64
nonce_admin = base64.b64decode(known_nonce)
tag_admin = base64.b64decode(known_tag)
pt1 = b"B" * 64
r.recvuntil(b"> ")
r.sendline(b"0")
r.recvuntil(b"Plaintext:")
r.recvuntil(b"> ")
r.sendline(pt1.hex().encode())
r.recvuntil(b"Nonce:")
r.recvuntil(b"> ")
r.sendline(nonce_admin.hex().encode())
line = r.recvline().decode().strip()
# dạng: pt.hex()='...' = ct.hex()='...', tag.hex()='...'
import re
m = re.search(
r"ct\.hex\(\)='([0-9a-f]+)'.*tag\.hex\(\)='([0-9a-f]+)'",
line
)
ct1_hex, tag1_hex = m.group(1), m.group(2)
ct1 = bytes.fromhex(ct1_hex)
tag1 = bytes.fromhex(tag1_hex)
log.success(f"pt1 = {pt1}")
log.success(f"ct1 = {ct1.hex()}")
log.success(f"tag1 = {tag1.hex()}")
keystream = xor(ct1, pt1) # KS[0:len(pt1)]
pt0 = b"Hello GlacierCTF"
ct0 = xor(pt0, keystream[:len(pt0)])
log.success(f"pt0 = {pt0}")
log.success(f"ct0 = {ct0.hex()}")
H_candidates = list(recover_possible_auth_keys(
ad, ct0, tag_admin,
ad, ct1, tag1
))
H = H_candidates[0]
log.success(f"H = {H}")
pt2 = b"AAAA" + ADMIN_SECRET + b"BBBB"
ct2 = xor(pt2, keystream[:len(pt2)]) # cùng nonce_admin nên cùng KS
tag2 = forge_tag(H, ad, ct0, tag_admin, ad, ct2)
log.success(f"pt2 = {pt2}")
log.success(f"ct2 = {ct2.hex()}")
log.success(f"tag2 = {tag2.hex()}")
r.recvuntil(b"Choose action:")
r.recvuntil(b"> ")
r.sendline(b"1")
r.recvuntil(b"Ciphertext:")
r.recvuntil(b"> ")
r.sendline(ct2.hex().encode())
r.recvuntil(b"Nonce:")
r.recvuntil(b"> ")
r.sendline(nonce_admin.hex().encode())
r.recvuntil(b"Tag:")
r.recvuntil(b"> ")
r.sendline(tag2.hex().encode())
print(r.recvall().decode("utf-8", "ignore"))
Bug: Solve script trên chỉ solve được trên Local vì khi request tới server nó chạy quá lâu nên mình bị timeout trước khi gửi hết toàn bộ request.
Có một cách xử lý đó là thay vì gửi rồi nhận từng request một thì mình có thể gửi 1 lúc 64 request rồi thực hiện phân tích trên từng request rồi rút ra sẽ nhanh hơn là gửi và nhận từng cái 1.
Solve script (cái này được viết bởi chat GPT):
import os
import string
import sys
from pwn import *
from gcm_exploit import *
import base64
# r = remote("challs.glacierctf.com",13373,timeout=5)
REQUEST_COUNT = 0
r = remote("127.0.0.1",1337)
data = r.recvuntil(b'Choose action:')
print(data)
with open("output.txt","w") as f:
f.write(str(data))
def get_size(io, payload):
global REQUEST_COUNT
try:
io.sendline(b"0")
io.sendlineafter(b"Plaintext:\n> ", payload.hex().encode())
nonce = os.urandom(16)
io.sendlineafter(b"Nonce:\n> ", nonce.hex().encode())
REQUEST_COUNT += 1
io.recvuntil(b"Storage left: ")
line = io.recvline().decode().strip()
raw_size = int(line.split('/')[0])
compressed_size = raw_size - (REQUEST_COUNT * 16)
io.recvuntil(b"Choose action:\n> ")
return compressed_size
except Exception as e:
print(f"Error in get_size: {e}")
print(f"Request Count: {REQUEST_COUNT}")
return 999999
def leak_secret(io, prefix):
known = prefix
charset = string.ascii_letters + string.digits + "+/="
print(f"[*] Leaking secret for prefix: {prefix}")
global REQUEST_COUNT
while True:
candidates = {}
print(f"[*] Batching {len(charset)} requests for position {len(known)}")
payloads = []
for char in charset:
probe = (known + char).encode()
payloads.append((char, probe))
for char, probe in payloads:
io.sendline(b"0")
io.sendline(probe.hex().encode())
nonce = os.urandom(16)
io.sendline(nonce.hex().encode())
for i, (char, probe) in enumerate(payloads):
try:
REQUEST_COUNT += 1
io.recvuntil(b"Storage left: ")
line = io.recvline().decode().strip()
raw_size = int(line.split('/')[0])
compressed_size = raw_size - (REQUEST_COUNT * 16)
io.recvuntil(b"Choose action:\n> ")
candidates[char] = compressed_size
except Exception as e:
print(f"Error in batch receive: {e}")
print(f"Request Count: {REQUEST_COUNT}")
return known[len(prefix):]
min_size = min(candidates.values())
best_chars = [c for c, s in candidates.items() if s == min_size]
if len(best_chars) == 1:
best_char = best_chars[0]
known += best_char
sys.stdout.write(f"\r[+] Found: {known}")
sys.stdout.flush()
if best_char == "\n" or len(known) > 100:
break
if best_char == "=":
pass
if len(known) - len(prefix) >= 24:
if len(known) - len(prefix) >= 24:
break
else:
print(f"\n[!] Ambiguity: {best_chars} with size {min_size}")
break
print(f"\n[+] Leaked: {known}")
return known[len(prefix):]
nonce_b64 = leak_secret(r, "[+] Nonce: ")
tag_b64 = leak_secret(r, "[+] Tag: ")
nonce_admin = base64.b64decode(nonce_b64)
tag_admin = base64.b64decode(tag_b64)
print(nonce_admin,"\n")
print(tag_admin)
ADMIN_SECRET = b"Glacier CTF Open"
MAX_STORAGE = 1 << 16
ad = b"GlacierCTF2025"
pt1 = b"B" * 64
r.sendline(b"0")
r.recvuntil(b"Plaintext:\n> ")
r.sendline(pt1.hex().encode())
r.recvuntil(b"Nonce:\n> ")
r.sendline(nonce_admin.hex().encode())
line = r.recvline().decode().strip()
print("[server log]:", line)
r.recvuntil(b"[+] Storage left: ")
_ = r.recvline()
r.recvuntil(b"Choose action:\n> ")
m = re.search(r"ct\.hex\(\)='([0-9a-f]+)'.*tag\.hex\(\)='([0-9a-f]+)'", line)
ct1_hex, tag1_hex = m.group(1), m.group(2)
ct1 = bytes.fromhex(ct1_hex)
tag1 = bytes.fromhex(tag1_hex)
# ct1_hex, tag1_hex = m.group(1), m.group(2)
# ct1 = bytes.fromhex(ct1_hex)
# tag1 = bytes.fromhex(tag1_hex)
# print(ct1)
# log.success(f"pt1 = {pt1}")
# log.success(f"ct1 = {ct1.hex()}")
# log.success(f"tag1 = {tag1.hex()}")
keystream = xor(ct1, pt1) # KS[0:len(pt1)]
pt0 = b"Hello GlacierCTF"
ct0 = xor(pt0, keystream[:len(pt0)])
# log.success(f"pt0 = {pt0}")
# log.success(f"ct0 = {ct0.hex()}")
H_candidates = list(recover_possible_auth_keys(
ad, ct0, tag_admin,
ad, ct1, tag1 ))
H = H_candidates[0]
print(H)
# log.success(f"H = {H}")
pt2 = b"AAAA" + ADMIN_SECRET + b"BBBB"
ct2 = xor(pt2, keystream[:len(pt2)]) # cùng nonce_admin nên cùng KS
tag2 = forge_tag(H, ad, ct0, tag_admin, ad, ct2)
print(tag2)
r.recvuntil(b"Choose action:")
r.recvuntil(b"> ")
r.sendline(b"1")
r.recvuntil(b"Ciphertext:")
r.recvuntil(b"> ")
r.sendline(ct2.hex().encode())
r.recvuntil(b"Nonce:")
r.recvuntil(b"> ")
r.sendline(nonce_admin.hex().encode())
r.recvuntil(b"Tag:")
r.recvuntil(b"> ")
r.sendline(tag2.hex().encode())
print(r.recvline().decode("utf-8", "ignore"))
Chall 4
from Crypto.Cipher import AES
from os import urandom
from signal import alarm
from secret import PoW, flag
PoW(26)
alarm(30)
gen = lambda: urandom(12)
randbit = lambda: gen()[0] & 1
key, nonce = urandom(16), gen()
new = lambda: AES.new(key, AES.MODE_GCM, nonce)
s = [gen(), gen()]
while cmd := input("> "):
if cmd == "tag":
cipher = new()
cipher.update(s[0])
cipher.encrypt(s[1])
print(f"tag: {cipher.digest().hex()}")
elif cmd == "u1":
s[randbit()] = gen()
elif cmd == "u2":
s[randbit()] += gen()
if input(f"tag: ") == new().digest().hex():
print(flag)
Và file secret.py:
import hashlib
import os
import random
import string
colors = ['\033[94m', '\033[96m', '\033[95m']
reset = '\033[0m'
banner = ''.join(random.choice(colors) + char + reset if char != ' ' else char for char in open("banner.txt", "r").read())
colors = ["\033[0;32m", "\033[0;33m", "\033[0;34m", "\033[0;35m", "\033[0;36m", "\033[0;37m", "\033[0;31m", "\033[38;5;248m", "\033[0m"]
green, yellow, blue, purple, cyan, white, red, grey, reset = colors
flag = ""
for c in open("flag.txt", "r").read(): flag += colors[random.randrange(0, 6)] + c
flag += reset
def PoW(bits):
print(banner)
n = random.randrange(0, 2**bits)
a = "".join(random.choices(string.ascii_letters, k=20)).encode()
hsh = hashlib.md5(str(n).encode() + a).digest()
print(f"md5(str(n).encode() + {a}).hexdigest() = {bytes.hex(hsh)}")
if int(input(f"Input the decimal result of n within range(2**{bits}): ")) != n:
exit()
Phân tích source code: Đầu tiên ta có code giải PoW như sau:
from pwn import *
from utils import *
import re
context.log_level = 'debug'
io = process(['python3', 'chall.py'])
io.recvuntil(b'md5')
line = io.recvline().decode()
m = re.search(r"b'([^']+)'.*=\s*([a-fA-F0-9]{32})", line)
assert m is not None
a = m.group(1)
b = m.group(2)
for n in range(2**26):
hsh = hashlib.md5(str(n).encode()+a.encode()).hexdigest()
if hsh == b:
print(f"Found n: {n}")
break
io.sendline(str(n).encode())
io.interactive()
Tiếp theo ta sẽ xem logic của bài này đang làm gì.
Đầu tiên ta có key và nonce được khởi tạo cố định:
key, nonce = urandom(16), gen()
Và một cặp giá trị s = [gen(), gen()] cũng được khởi tạo ngẫu nhiên. Kế đến là logic chính của bài: Bài cho nhập vào 3 option tag, u1 và u2. Với option tag thì server sẽ sử dụng s[0] làm AAD và s[1] làm plaintext rồi tính tag tạo bởi hai giá trị này.
u1 sẽ cập nhật lại ngẫu nhiên một trong hai giá trị s[0] hoặc s[1] còn u2 sẽ cộng thêm một giá trị ngẫu nhiên vào một trong hai giá trị s[0] hoặc s[1].
Để lấy lại flag thì ta phải nhập đúng tag được tạo ra new().digest().hex() tức là AES-GCM nhưng cả AAD và Ciphertext đều rỗng.
from Crypto.Cipher import AES
import os
key, nonce = os.urandom(16), os.urandom(12)
a = AES.new(key, AES.MODE_GCM, nonce)
tag = a.digest().hex()
print(tag)
Vậy trong trường hợp này thì tag sẽ được tính như thế nào? Từ sơ đồ tính tag mà ta đã học ở trên thì trong trường hợp AAD và Ciphertext rỗng thì các block đều sẽ là block 0. Cho nên $T = Enc_{k}(J_0)$ trong đó $J_0$ là nonce. Vì $J_0$ lúc này có độ dài là 12 bytes cho nên nó sẽ được padding theo tiêu chuẩn và tính:
if len(nonce) == 12:
J0 = nonce + b'\x00\x00\x00\x01'
Vậy bây giờ ta cần tìm lại nonce.
Về độ lớn và phân chia các block: AES-GCM quy ước 1 block có độ lớn là 16 bytes. Ở đây s[0] và s[1] đều có độ lớn là 12 bytes cho nên nó sẽ được pad thêm 4 bytes cuối để đủ 1 block. Lúc này ta sẽ có 2 block là s[0] || padding và s[1] || padding ngoài ra sẽ có thêm block cuối để lấy độ dài.
Bây giờ giả sử ta chọn option u1 và nó sẽ thực hiện update plaintext.